ハフマンデコードモジュール 構成案
ハフマンデコード部分の構成を考えます。
ハフマンデコード部分は様々な構成方法がありえます。そこで前提条件として以下のように考えました。
・現在のFPGAボードにはどう設計しても入らない、かつFPGA内部のリソースに詳しくないので、とりあえずリソースを小さくすることは考えない。
・ソフトウェアからモジュールにデータを送る部分で多数のクロックを使うと思われる(データが飛び飛びでやってくる)。よって、とりあえずここの処理時間はクリティカルにはならない。しかし、後ほどDMA転送を行うつもりなので、ハフマンデコードはなるべく少ないクロックで計算を終わる。
以上を仮の条件とします。
ハフマンデコード部分全体のデータの流れは以下のようになります。
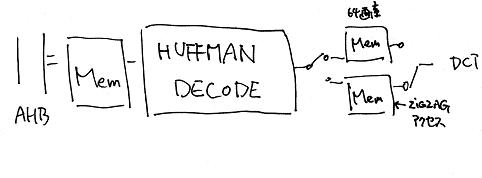
(まだ考察レベルなので手書きで、、、、)
AHBバスからメモリにデータを書き込みます。メモリにデータがあり、かつ後段の64画素メモリのダブルバッファに書き込めるときにハフマンデコードモジュールが動作します。ダブルバッファは設計済みのDCTモジュールにつながります。その際のメモリアクセスのアドレス順序をDCTのジグザグオーダにします。
ここまでは確定です。
次に本題のハフマンデコード演算部分ですが、これまでに仮決めしてきたようにリソースを気にしないのと、テーブルの処理は最初の画像1枚しか行わない、必要クロック数を減らすという目標のために、IJGのソースコードに有ったキャッシュ演算を16bitまで拡張した手法を用います。
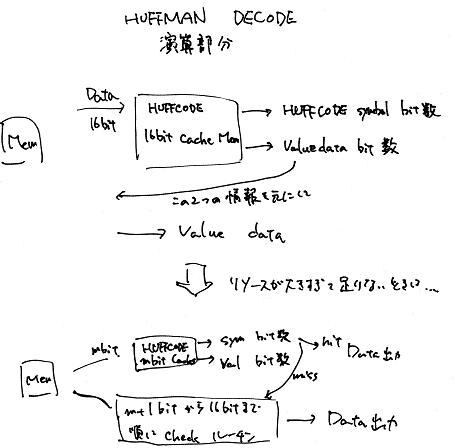
2の16乗個のキャッシュデータ計算と書き込みが必要となりますが、これは最初の画像1枚が出力される前にソフトウェア側で計算して書き込みます。以降の画像ではこの書き込みは発生しないのでFPSには大きな影響はありません。
もし、このメモリリソースが大きすぎたり、書き込み時間が長すぎた場合は図の下側のようにキャッシュを適当なmbitまでに縮小し、それがhitすればそのまま続行、hitしなければ別のハードウェアを設計して1ビット増やしてチェックを繰り返すようにします。16bitキャッシュがうまく動作すればこの部分は設計しなくて良いのでとりあえずは16bitキャッシュの方針で設計を進めます。
後記:この考え方は間違ってました。16bit キャッシュを用いた場合でも有効ビット数が15bit以下でキャッシュアクセスすると間違った値が出力されます。よって図の下側のハードウェアは必ず必要になります。
これまで見てきたようにJPEGのハフマンデータは、ハフマン符号と実際のデータが順に繰り返されています。それぞれを順番に繰り返し処理していけばよいのですが、ハフマンコードのキャッシュは16bitのアクセスした後に符号の必要ビット数が確定します。すなわち、
・ハフマン符号 - ハフマンコードキャッシュにアクセスした後に実際のビット数が確定
・数値データ - 実際の数値データ処理フェーズの前に必要ビット数が確定している
というな違いがそれぞれのフェーズにあることを考えて設計する必要があります。
様々なことを考えて、とりあえずざっくりとした案が以下の図です。
(まだ詳細をチェックしていませんので、これからいろいろ変更していきます)
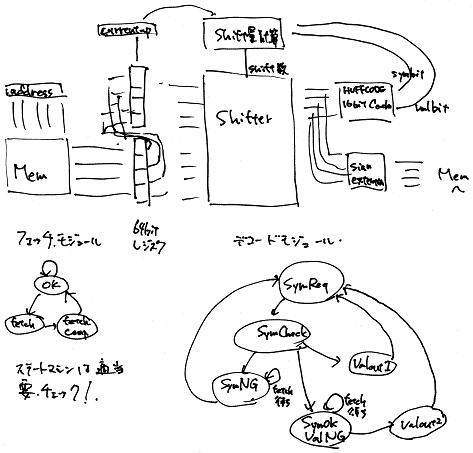
ハフマン符号最大16bit,数値データ最大10bitですが、バイトアラインでFFというデータが入った場合マーカとの区別のための00というデータが挿入されています。よって、それぞれ最大32bit,26bitとなる可能性があります。
AHBが32bit幅なのでメモリは32bit幅のものを使用します。データ自体は、当然現在の32bitと次の32bitにまたがる可能性があります。
よって、図のように64ビットのフェッチレジスタを作り、フェッチ部分とデコード部分に分けます。
64bitのレジスタには、現在何ビットの有効データが入っているかを示すcurrent_pレジスタが付属しています。
有効データが32ビット以下になると、フェッチ可能ならフェッチを行います。
その際メモリからの出力にFF00があれば、00を取り除いてフェッチします。マーカであればその情報を記録します。
これは2つステートを持つステートマシンで構成できそうですが、フェッチ直後の状態を右側のステートマシンが区別した方が良いと思われたので、とりあえずステート3つにしました。
(ステートマシンについては、今後詳しい考察が必要です。)
右側のデコード部には、先頭から16bitを取ってきてキャッシュに渡したり、確定したビット数分の数値データを取り出すためにシフタが必要となります。このシフト量をステートに応じて演算する部分が必要となります。
ステートマシンはキャッシュへの要求ステート(SymReq)、その出力から符号ビット数や数値データビット数を確定するフェーズ(SymCheck)、実際に出力するフェーズ(ValOUT1)の3つを基本としました。
データが常に充分ある場合は、一番内側の3つのステートをくるくる回ります。
しかし、実際にはフェッチレジスタにデータが不足している状態も発生しますので、その状態に応じてステートを3つ足しました。
SymCheckのステートで、データが足りていればValOUT1へ遷移しますが、ハフマン符号自体のデータが不足している場合はSymNGへ遷移します。
(16bitのデータがフェッチレジスタに足りてないときも適当な値を追加してキャッシュへアクセスします。そうしないと、データの最期でデコードできなくなります。その有効ビット数を記録しておき、SymCheckのステートで比較します。)
ハフマン符号自体は充分データがあったが、続く数値データが不足する場合は、SymOK,ValNGのステートへ遷移します。
これら二つのステートでは、左側のフェッチステージのステートマシンがフェッチを行うまで同じステートにとどまります。フェッチされた時に、ハフマン符号待ちの場合は再びキャッシュアクセスを行います。数値データ待ちの場合は数値データを出力します。
以上がざっくり考えた案です。詳細を考察してこれで正しく動くのか調べなければなりません。ステートもうまくやれば少し減らせるかもしれません(増やさないといけないかもしれませんが、、、)。
詳細を考察した後にC言語で検証する訳ですが、IJGのコードに埋め込むのがどうも難しいです。。。。。。
IJGのライブラリはMCU単位でデコードしていく構造になっていますので、メモリのフェッチ待ちをうまくチェックする構造にするのは不可能な気がする。。。。。
うーん、困った。。。。