IJGソフト内部 ハフマン符号化 1
IJG のjpeglibのハフマンデコード部分のソースコードを読みました。
ハフマンデコード部分は非常に読みにくいソースコードになっています。
綺麗に説明するのは難しいですが、多くのシステムで使用されている非常にユーザ数の多いソースコードなので、今後ソースコードを読む人もいると思いますのでメモ程度に残します。
ハフマンデコード部分は、jdhuff.c と jdhuff.h に記述されています。
jdhuff.cの中の jpeg_make_d_derived_tbl()中で、jpeg規格書にあったような内部テーブル(maxcode,mincode等)が作成されています。
jpeg規格書と2箇所異なる部分がありますので、ここに書いておきます。
(1)jpeg規格書では、maxcode(k)という配列と現在のcodeを順に比較することによって、codeのビット数を決定し、その後code - mincode(k) + VALPTR(K) という計算を行うことによって実際の変換後の値の入った配列のINDEXを得ていました。
IJGのソフトウェアでは、その code - mincode(k) + VALPTR(k)の部分をまとめて、code + valoffset(k) としています。 -mincode(k) + VALPTR(K)を先に計算したオフセット値のインデックスにしています。valoffsetはマイナスの値になります。よって実際の値を取り出すためには、
symbol = huffval[code + valoffset[k]] という演算になります。
(2)IJGソフトウェアでは、高速化のために8bitのコード全ての値を一度に返すキャッシュのような内部テーブルを持っています。
look_nbits, look_symという二つの配列がそのテーブル用です。
以前の例の場合、この配列は以下のようなものになります。
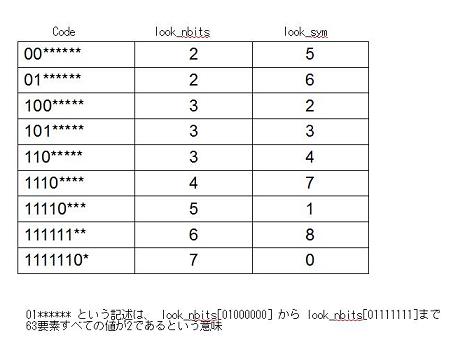
このような配列を作っておくことによって、とりあえずデータ列の現在の先頭位置から8ビットまとめてコードを取得し、その値をインデックスとしてこの配列にアクセスすれば、デコードされた値と実際に使われたビット数が分かります。この例の場合はすべてのコードが8ビット以内に入っていますが、入りきれない場合は対応するインデックスのlook_nbitsには0が入っているようになっているので、そこから9ビット以上のコードであることが判定でき、9ビット以上のチェックを開始します。
これがキャッシュのような仕組みとなっています。
キャッシュにヒットした場合は、値をダイレクトに取得できます。データ列の現在の先頭位置をlook_nbitsで得られた値だけ進めて次の処理がはじまります。
ハフマン符号は、存在確率の高いものに対して短い符号を与えますので、8ビット以下の符号が一度に値が分かるキャッシュは非常に有効に効くことが分かります。かなり大きな割合がこの中に入りますので、実際にmaxcode等を用いて9ビット以上の符号をデコードすることはたまにしか発生しないと予想されます。